预测基因组变异的效应是一个研究热点。随着全基因组测序技术的普及,我们积累了海量的基因组数据,但如何准确解读这些变异的生物学意义,尤其是非编码区变异的功能,仍然是一个巨大的挑战。
为了解决这一挑战,来自加州大学伯克利分校的Yun S. Song等团队提出了GPN-MSA(基于多序列比对的基因组预训练网络),相关成果发表在《Nature Biotechnology》杂志上(A DNA language model based on multispecies alignment predicts the effects of genome-wide variants)。这一模型通过整合多物种的全基因组比对数据,显著提升了基因组范围内变异的致病性预测能力,尤其在非编码区变异的解读上。
![图片[1]-Nat. Biotechnol|仅需4卡3.5小时训练的DNA语言模型助力变异效应预测 --实验盒](https://www.shiyanhe.com/wp-content/uploads/2025/02/Pasted-image-20250205100603-1024x486.png)
背景:基因组变异预测的困境与突破
基因组变异效应预测(VEP)对于罕见病诊断、药物开发以及精准医学的推进至关重要。然而,尽管蛋白质语言模型在预测错义变异效应方面表现出色,但DNA语言模型在复杂基因组(如人类基因组)上的表现一直不尽如人意。人类基因组中约98%的区域是非编码区,这些区域的功能复杂且难以预测。以往的DNA语言模型在处理这些复杂性时往往力不从心,尤其是在没有大量标注数据的情况下进行无监督学习时。
GPN-MSA的出现,正是为了解决这一难题。该模型基于多物种全基因组比对(MSA),利用不同物种间的进化信息来增强变异效应的预测能力。这种方法不仅考虑了序列本身的上下文信息,还引入了物种间的进化约束和适应性信息,从而为变异效应预测提供了更丰富的生物学背景。
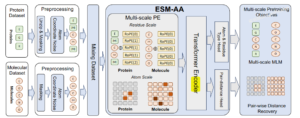
GPN-MSA模型的核心技术
![图片[2]-Nat. Biotechnol|仅需4卡3.5小时训练的DNA语言模型助力变异效应预测 --实验盒](https://www.shiyanhe.com/wp-content/uploads/2025/02/Pasted-image-20250205100259-806x1024.png)
多物种全基因组比对的利用
GPN-MSA的核心在于其对多物种全基因组比对(MSA)的深度利用。研究人员使用了100种脊椎动物的全基因组比对数据,通过处理和筛选,构建了一个高效的训练框架。模型不仅学习了单个物种的序列信息,还通过比对信息学习了不同物种间的进化关系。这种跨物种的学习方式,使得模型能够更好地识别功能保守区域和潜在的功能变异。
Transformer架构的应用
GPN-MSA采用了灵活的Transformer架构,这种架构在自然语言处理领域已经取得了巨大成功。Transformer通过自注意力机制,能够处理长距离的序列依赖关系,这对于基因组序列分析尤为重要。在GPN-MSA中,Transformer架构被用于处理MSA的列(位置)和行(物种)信息,从而为每个位置生成高维上下文嵌入。这种设计使得模型能够同时考虑序列的上下文和进化信息,从而更准确地预测变异效应。
高效的训练策略
GPN-MSA的训练策略也非常关键。研究人员选择在基因组的保守区域进行训练,这些区域更有可能包含功能相关的变异。此外,模型还采用了加权交叉熵损失函数,对重复序列和保守序列分别进行降权和加权,以减少模型对重复序列的过度拟合,并增强对功能重要区域的学习能力。这种训练策略不仅提高了模型的预测性能,还大大减少了计算资源的需求。GPN-MSA仅用了3.5小时在4个NVIDIA A100 GPU上完成训练,相比以往的模型,如Nucleotide Transformer,其计算效率显著提高。
GPN-MSA的性能表现
GPN-MSA在多个基准测试中表现出色,显著优于现有的DNA语言模型和其他广泛使用的预测工具。以下是其在几个关键数据集上的表现:
ClinVar数据集
在ClinVar数据集上,GPN-MSA能够有效区分致病性错义变异和gnomAD中的常见变异。其AUROC(接收者操作特征曲线下面积)达到了0.963,远高于其他模型,如Nucleotide Transformer和HyenaDNA。这表明GPN-MSA在预测致病性变异方面具有很高的准确性。
COSMIC数据集
在COSMIC数据集上,GPN-MSA用于区分频繁出现的癌症体细胞错义变异和gnomAD中的常见变异。其AUPRC(精确率-召回率曲线下面积)达到了0.874,同样优于其他模型。这说明GPN-MSA在识别潜在的癌症驱动变异方面具有显著优势。
OMIM数据集
在OMIM数据集上,GPN-MSA用于区分与孟德尔疾病相关的调控变异和gnomAD中的常见变异。其AUPRC达到了0.923,再次证明了其在非编码区变异预测上的强大能力。这一结果表明,GPN-MSA不仅能够准确预测编码区变异的效应,还能有效解读非编码区变异的功能,这对于罕见病诊断和遗传咨询具有重要意义。
gnomAD数据集
在gnomAD数据集上,GPN-MSA用于富集罕见变异(单例)与常见变异(MAF>5%)的极端有害性评分。其富集比达到了17.6,远高于其他模型。这表明GPN-MSA能够更好地识别那些在人群中频率较低但可能具有较大生物学影响的变异。
![图片[3]-Nat. Biotechnol|仅需4卡3.5小时训练的DNA语言模型助力变异效应预测 --实验盒](https://www.shiyanhe.com/wp-content/uploads/2025/02/Pasted-image-20250205100331-1024x804.png)
GPN-MSA的潜在应用
GPN-MSA的出现为基因组变异效应预测带来了新的希望,其高效的计算性能和强大的预测能力使其在多个领域具有广泛的应用前景。
罕见病诊断
罕见病往往由基因突变引起,而许多罕见病的致病突变位于非编码区。GPN-MSA能够准确预测非编码区变异的效应,为罕见病的诊断提供了新的工具。通过分析患者的全基因组数据,结合GPN-MSA的预测结果,医生可以更准确地识别潜在的致病变异,从而提高罕见病的诊断率。
药物开发
在药物开发过程中,了解基因变异的功能对于靶点发现和药物设计至关重要。GPN-MSA能够预测变异对基因表达和功能的影响,有助于研究人员识别潜在的药物靶点,并评估药物对不同基因型患者的疗效和安全性。
进化生物学研究
GPN-MSA利用多物种比对信息进行训练,这使其能够反映不同物种间的进化关系。通过分析变异在进化上的保守性,研究人员可以更好地理解基因组的进化历程,以及不同物种间基因功能的保守性和差异性。
未来研究方向
尽管GPN-MSA已经取得了显著的成果,但仍有许多值得进一步探索的方向。例如,如何将更多的功能基因组学数据(如转录组、表观基因组等)整合到模型中,以进一步提高预测的准确性;如何优化模型架构和训练策略,以更好地处理长序列和复杂的进化关系;以及如何将模型应用于其他物种的基因组变异预测等。此外,如何将GPN-MSA的预测结果与临床数据相结合,以实现更精准的医学应用,也是未来研究的重要方向。
参考
Benegas, Gonzalo, Carlos Albors, Alan J. Aw, Chengzhong Ye, and Yun S. Song. “A DNA language model based on multispecies alignment predicts the effects of genome-wide variants.” Nature Biotechnology (2025): 1-6.
![图片[4]-Nat. Biotechnol|仅需4卡3.5小时训练的DNA语言模型助力变异效应预测 --实验盒](https://www.shiyanhe.com/wp-content/uploads/2025/01/wx-banner-website-2021.png)















暂无评论内容